SOTA in Scene Text Recognition 2022: A Quick Overview

Example of STR
Scene Text Recognition (STR) is one of the more challenging tasks in computer vision, especially considering how much variation is observable in these images. However, with each passing year, the state-of-the-art (SOTA) gets pushed closer and closer to near-perfect predictions.
In this quick review, I intend to briefly touch upon the best-performing models that have been recorded at Papers With Code, which is a great site, not just for experts to identify what the current SOTA is, but also for beginners who wish to get their feet wet by working directly with the code of interest. (Not sponsored BTW. :-P)
The state-of-the-art models for Scene Text Recognition (STR) in 2022 are:
-
PARSeq
-
S-GTR
-
CDistNet
-
DPAN
-
Yet Another Text Recognizer
- PARSeq
- S-GTR
- CDistNet
- DPAN
- Yet Another Text Recognizer
- Final Thoughts
PARSeq
Links
Overview
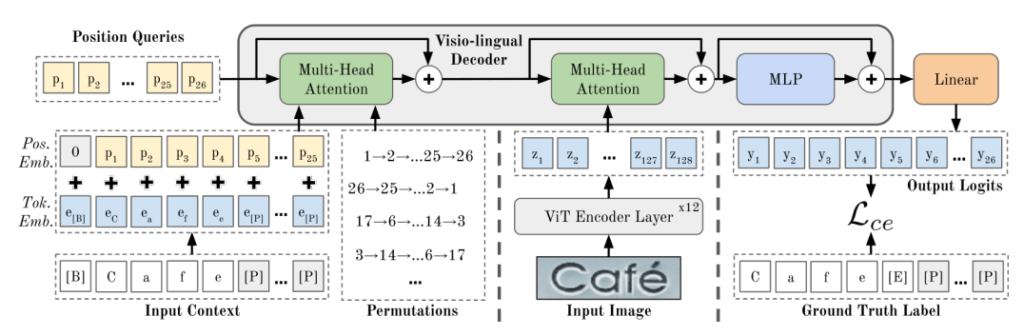 PARSeq Model Architecture
PARSeq Model Architecture
Permuted Autoregressive Sequence (PARSeq) models are primarily inspired by a technique known as Permutation Language Modeling (PLM), which was first introduced by a paper called XLNet. The main idea behind the approach was to use multiple permutations of the target sequence such that the model not only learns a language model (LM) but also learns how to predict in context-free scenarios (no dependency between characters of the word). The Multi-Head Attention mechanism handles these permutations while still preserving the original order in the input and output sequences.
As you can probably tell from the model architecture, this description is a massive over-simplification. So, check out this other article of mine for a more thorough explanation.
S-GTR
Links
-
Paper: Visual Semantics Allow for Textual Reasoning Better in Scene Text Recognition
-
Code: GitHub (Quick note: Unfortunately the codebase was full of errors the last time I checked, so I wasn’t able to get it to run)
Overview
 S-GTR Model Architecture
S-GTR Model Architecture
The main idea proposed in the paper is a module called the Graph-based Textual Reasoning (GTR) model, which is appendable in parallel to a language model (LM) in a given STR architecture. Accordingly, this module enables the utilization of spatial reasoning to refine the predictions made by the LM.
The combination of GTR with a segmentation-based STR baseline is known as S-GTR. In this architecture, the segmentation maps identified by the segmentation-based STR baseline are passed to the lower branch while the text prediction is sent to the LM in the upper branch. Next, the segmentation maps pass through the with Feature Ordering + GTR to form a set of predictions. Similarly, the language model refines the text predictions to create a new set of predictions.
Accordingly, there are 3 sets of text predictions by 3 modules:
-
Seg-based Visual Recognition prediction
-
LM prediction
-
GTR prediction
Therefore, these 3 results are combined using dynamic fusion to form the final prediction.
CDistNet
Links
-
Paper: CDistNet: Perceiving Multi-Domain Character Distance for Robust Text Recognition
-
Code: GitHub
Overview
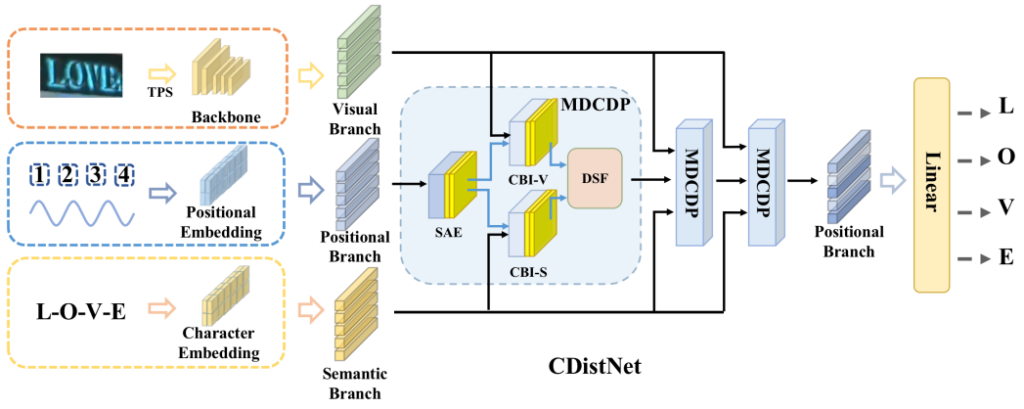 CDistNet Model Architecture
CDistNet Model Architecture
The main contribution behind CDistNet is the Multi-Domain Character Distance Perception (MDCDP) module which is able to combine both visual information and semantic information.
The MDCDP module accepts input in 3 branches:
-
The visual branch (details inferred from pixels)
-
The positional branch (the positional embeddings)
-
The semantic branch (details on relationships among characters)
Accordingly, the output of the MDCDP module is a matrix that represents the feature-character alignment.
Moreover, CDistNet is built using multiple such MDCDP modules and as it passes each module, the matrix gets more and more refined. As a result, the character for each position is easily inferrable using a simple linear layer + softmax combination.
DPAN
Links
-
Paper: Look Back Again: Dual Parallel Attention Network for Accurate and Robust Scene Text Recognition
-
Code: GitHub (This is an unofficial implementation; The official implementation has not been added)
Overview
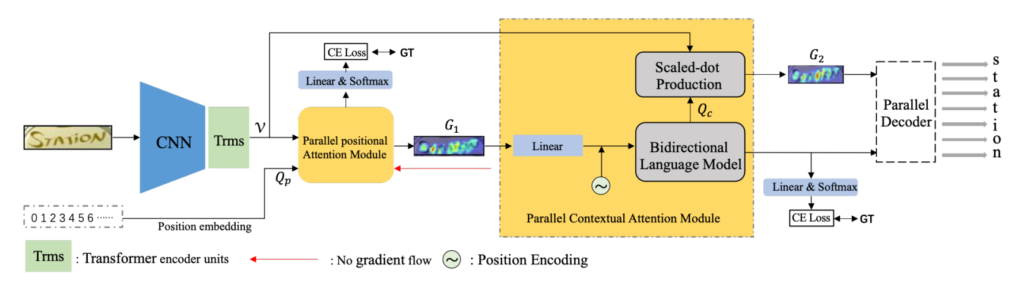 DPAN Model Architecture
DPAN Model Architecture
Lyu et al, in their paper, proposed something known as the Parallel Attention Module which improved the flexibility and efficiency of attention mechanisms. As a result, they managed to improve attention related to positional information (Parallel Positional Attention Module / PPAM). The authors of DPAN show the problems of this approach and proposes a module called the Parallel Contextual Attention Module (PCAM). This module focuses on capturing the semantic details of the text.
Within the PCAM module, a Bidirectional Language Model is used to extract contextual information. Additionally, the result also passes through another attention mechanism (Scaled-dot Production). Next, both the outputs of PCAM are fed into a parallel decoder (see the VSFD class in the code base). Somewhat similar to S-GTR, DPAN too calculates the losses of multiple paths (output of PPAM, output of PCAM, output of the parallel decoder).
Yet Another Text Recognizer
Links
-
Paper: Why You Should Try the Real Data for the Scene Text Recognition
-
Code: GitHub (This is the official repo provided, but I was unable to locate the exact code for it)
Overview
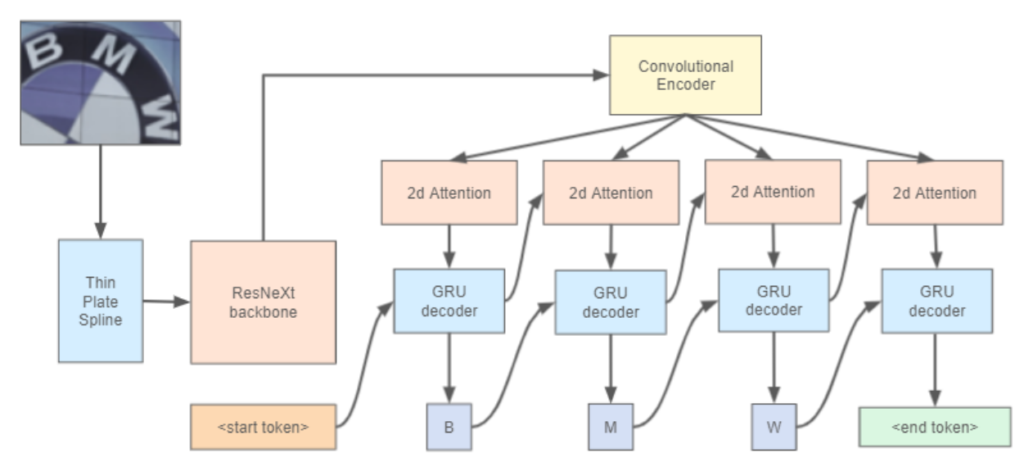 Yet Another Text Recognizer Model Architecture
Yet Another Text Recognizer Model Architecture
The primary contribution of the paper is the empirical proof that using more real images for training tends to result in better performance. The author uses a dataset known as the “OpenImages V5 text spotting dataset” to drive this point.
In addition to the previously mentioned observation, the paper also proposes a novel model architecture that achieved performance comparable to the state-of-the-art. First, a Thin-Plate Spline transformation is applied on the image, which is a transformation that rectifies irregular scene text images (see the ASTER paper for more details). Next, the transformed image is fed to a ResNeXt backbone which acts as a feature extractor.
Finally, the result from the backbone is fed into a text recognition head, which has been adapted from the “Text branch” of the Yet Another Mask Text Spotter paper. It’s like a regular LSTM, but with the addition of an attention mechanism. So, the model generates characters until the
Final Thoughts
I hope this was helpful. Of course, a lot of the explanations are somewhat oversimplified, just to give an overview of the approach. Feel free to ask any follow-up questions or point out any mistakes.